spaCy is a powerful, feature-rich, open source Natural Language Processing (NLP) package in Python. It is excellent for quickly processing large volumes of text data, and picking out useful information.
Example use cases include:
- performing sentiment analysis to get the general feeling in extensive social media records.
- extracting named entities (people, places, dates, organisations, etc) from text files.
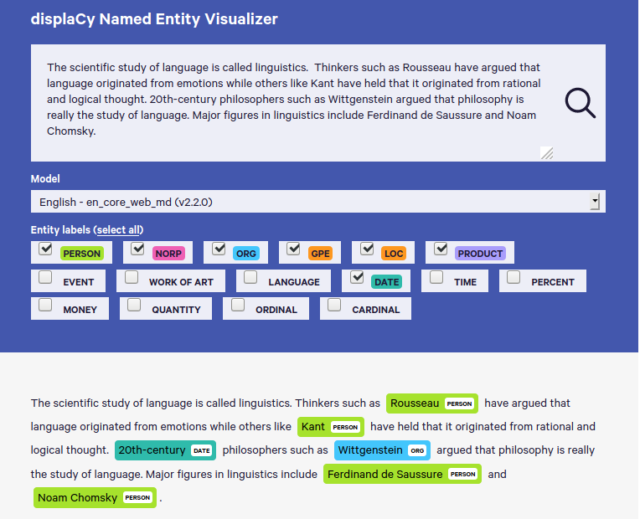
spaCy’s Named Entity Visualiser displaCy in action
Some of spaCy’s key features include:
-
Tokenization: splitting text into pieces (i.e words, numbers, punctuation marks, etc) termed ‘tokens’.
-
Part-of-Speech Tagging: classifying the tokens according to their syntactic functions, as nouns, verbs, conjunctions, determiners, etc.
-
Named Entity Recognition: getting the people, places, organisations, dates, events, landmark structures, nationalities, languages, etc. in the text.
-
Sentiment Analysis: getting the positivity or negativity score for a phrase, sentence, or entire document.
-
Lemmatization: getting the root form of the tokens, without inflections for tense, plural, case, gender, etc. This allows words like ‘was’ and ‘be’ to be interpreted as similar.
-
Dependency Parsing: getting the grammatical structure i.e the relationships between the tokens in terms of ‘subject’ or ‘object’ in the given contexts.
-
Sentence Boundary Detection: getting the sentences in the text (grouping together tokens that make up individual sentences, by identifying where sentences begin and end).
Getting Started
A straight-forward way to install spaCy would be:
pip install -U spacy
More options, such as installing from source, can be found at spaCy’s user guide.
spaCy offers pretrained models:
- Core models: ready to use for predicting named entities, part-of-speech tags and syntactic dependencies. Can be fine-tuned to better fit a case.
- Starter models: base models with pretrained weights for use in Transfer learning.
Basic Usage
# To install the small English core model
$ python -m spacy download en_core_web_sm
$ python
>>> import spacy
>>> nlp = spacy.load("en_core_web_sm")
>>> doc = nlp("Jack and Jill ran up the hill. The sun was shining bright.")
>>> for entity in doc.ents:
... print(entity.text, entity.label_)
...
Jack PERSON
Jill PERSON
>>> for token in doc:
... print(f"{token.text:<7}", token.lemma_, token.pos_, token.tag_, token.dep_,
... token.shape_, token.is_alpha, token.is_stop)
...
Jack Jack PROPN NNP nsubj Xxxx True False
and and CCONJ CC cc xxx True True
Jill Jill PROPN NNP conj Xxxx True False
ran run VERB VBD ROOT xxx True False
up up ADP IN prt xx True True
the the DET DT det xxx True True
hill hill NOUN NN pobj xxxx True False
. . PUNCT . punct . False False
The the DET DT det Xxx True True
sun sun NOUN NN nsubj xxx True False
was be AUX VBD aux xxx True True
shining shine VERB VBG ROOT xxxx True False
bright bright ADJ JJ advmod xxxx True False
. . PUNCT . punct . False False
Next Steps
spaCy has its very own Advanced NLP with spaCy course, which explains and demonstrates its features far more elaborately. It also includes coding exercises for an engaging learning experience. Please consider trying it out.