In database lingo, partitioning refers to the splitting of a table into smaller physical units. It helps speed up queries by reducing the amount of data to sift through, and enabling action on chunks rather than individual rows.

Photo by Young Shih on Unsplash
Partitioning is typically applied when the volume of data involved is considerably large. A common tactic is to place frequently used partitions in high-speed SSDs, while relegating stale data to cheaper (and hence slower) storage media.
Types of Partitions
PostgreSQL implements 3 partitioning mechanisms:
I. Range partitioning
Defines partitions using ranges of values from key column(s); with the lower bound being inclusive, and the upper exclusive. e.g.
CREATE TABLE covid_data (
day date NOT NULL,
country varchar(70) NOT NULL,
confirmed bigint NOT NULL,
deaths integer NOT NULL
)
PARTITION BY RANGE (confirmed); -- use no. of confirmed cases as partition key
CREATE TABLE covid_data_confirmed_upto_1e4 PARTITION OF covid_data
FOR VALUES FROM (0) TO (10000);
CREATE TABLE covid_data_confirmed_1e4_to_1e5 PARTITION OF covid_data
FOR VALUES FROM (10000) TO (100000);
...
II. List partitioning
Defines partitions by explicitly listing the values to appear in each one. e.g.
CREATE TABLE covid_data (
day date NOT NULL,
country varchar(70) NOT NULL,
confirmed bigint NOT NULL,
deaths integer NOT NULL
)
PARTITION BY LIST (left(upper(country), 1)); -- Partition by country 1st letter
CREATE TABLE covid_data_countries_a_to_d PARTITION OF covid_data
FOR VALUES IN ('A', 'B', 'C', 'D');
CREATE TABLE covid_data_countries_e_to_h PARTITION OF covid_data
FOR VALUES IN ('E', 'F', 'G', 'H');
...
III. Hash partitioning
Defines partitions using the remainder from applying a hash function to the partition key and dividing by a specified modulus. e.g.
CREATE TABLE covid_data (
day date NOT NULL,
country varchar(70) NOT NULL,
confirmed bigint NOT NULL,
deaths integer NOT NULL
)
PARTITION BY HASH (confirmed);
CREATE TABLE covid_data_confirmed_rem0 PARTITION OF covid_data
FOR VALUES WITH (MODULUS 10, REMAINDER 0); -- where hashed val ends in 0
CREATE TABLE covid_data_confirmed_rem1 PARTITION OF covid_data
FOR VALUES WITH (MODULUS 10, REMAINDER 1); -- where hashed val ends in 1
...
Example
Let’s carry out a simple experiment to gauge the practicality of partitioning.
1. Creating a database and loading the data
We’ll execute the following transaction as a script (create_tables.sql), and load sample data:
BEGIN;
CREATE TABLE covid_data (
day date NOT NULL,
country varchar(70) NOT NULL,
confirmed integer NOT NULL, -- int OK since all sample values < 2,147,483,647
deaths integer NOT NULL
);
CREATE TABLE covid_data_partitioned (
day date NOT NULL,
country varchar(70) NOT NULL,
confirmed integer NOT NULL,
deaths integer NOT NULL
)
PARTITION BY RANGE (day);
CREATE TABLE covid_data_2020q1 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2020-1-1') TO ('2020-4-1');
CREATE TABLE covid_data_2020q2 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2020-4-1') TO ('2020-7-1');
CREATE TABLE covid_data_2020q3 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2020-7-1') TO ('2020-10-1');
CREATE TABLE covid_data_2020q4 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2020-10-1') TO ('2021-1-1');
CREATE TABLE covid_data_2021q1 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2021-1-1') TO ('2021-4-1');
CREATE TABLE covid_data_2021q2 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2021-4-1') TO ('2021-7-1');
CREATE TABLE covid_data_2021q3 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2021-7-1') TO ('2021-10-1');
CREATE TABLE covid_data_2021q4 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2021-10-1') TO ('2022-1-1');
CREATE TABLE covid_data_2022q1 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2022-1-1') TO ('2022-4-1');
CREATE TABLE covid_data_2022q2 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2022-4-1') TO ('2022-7-1');
CREATE TABLE covid_data_2022q3 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2022-7-1') TO ('2022-10-1');
CREATE TABLE covid_data_2022q4 PARTITION OF covid_data_partitioned
FOR VALUES FROM ('2022-10-1') TO ('2023-1-1');
COMMIT;
$ createdb covid19_data
$ psql covid19_data
psql (14.4)
Type "help" for help.
covid19_data=> \i create_tables.sql
BEGIN
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
CREATE TABLE
COMMIT
covid19_data=> \copy covid_data FROM time-series-data.csv WITH (FORMAT CSV, HEADER);
COPY 181687
covid19_data=> \copy covid_data_partitioned FROM time-series-data.csv WITH (FORMAT CSV, HEADER);
COPY 181687
2. Evaluating performance
We’ll use EXPLAIN ANALYZE and a test query:
covid19_data=> EXPLAIN ANALYZE SELECT * FROM covid_data_partitioned WHERE day BETWEEN '2021-12-24' AND '2022-01-02';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------
Append (cost=0.00..792.22 rows=1990 width=21) (actual time=3.801..6.207 rows=1990 loops=1)
-> Seq Scan on covid_data_2021q4 covid_data_partitioned_1 (cost=0.00..395.62 rows=1592 width=21) (actual time=3.799..4.234 rows=1592 loops=1)
Filter: ((day >= '2021-12-24'::date) AND (day <= '2022-01-02'::date))
Rows Removed by Filter: 16716
-> Seq Scan on covid_data_2022q1 covid_data_partitioned_2 (cost=0.00..386.65 rows=398 width=21) (actual time=0.003..1.694 rows=398 loops=1)
Filter: ((day >= '2021-12-24'::date) AND (day <= '2022-01-02'::date))
Rows Removed by Filter: 17512
Planning Time: 0.297 ms
Execution Time: 6.386 ms
(9 rows)
covid19_data=> EXPLAIN ANALYZE SELECT * FROM covid_data WHERE day BETWEEN '2021-12-24' AND '2022-01-02';
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Seq Scan on covid_data (cost=0.00..3922.30 rows=1989 width=21) (actual time=12.840..15.892 rows=1990 loops=1)
Filter: ((day >= '2021-12-24'::date) AND (day <= '2022-01-02'::date))
Rows Removed by Filter: 179697
Planning Time: 0.138 ms
Execution Time: 15.985 ms
(5 rows)
covid19_data=>
3. Conclusion
After 16 runs on each table, it becomes evident that even though partitioned tables generally spend a bit more time planning, they more than make up for it with markedly faster query execution:
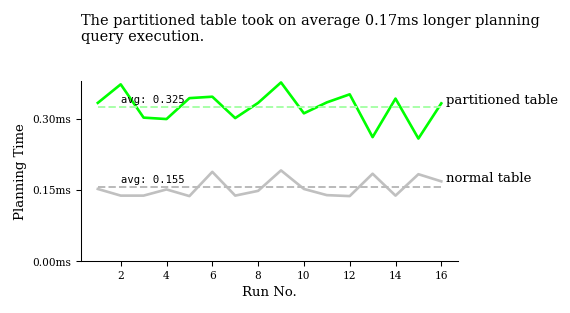
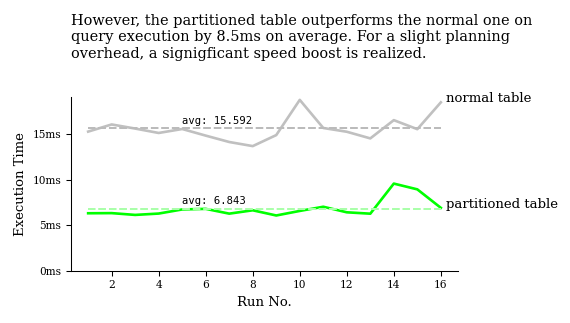
The larger the database, the greater the rewards partitioning bestows.
Further Reading
- Table partitioning in PostgreSQL docs.
- Database partitioning and indexing on Wikipedia.